
What's Cooking - Data Exploration Part 2
This post is a continuation of my pervious post, Data Exploration Part 1. The goal of these posts is to prep the data for the Kaggle competition What’s Cooking. The goal of this competition is to predict a recipe’s cuisine type based on the ingredients present in the recipe - in the previous post we reshaped the data and did some preliminary exploration of ingredient and cuisine frequencies. The data showed that there is great class imbalance that will be need to be addressed when a model is built. It also showed that there are many ingredients that are so prevalent, such as salt, that are not informative of the cuisine type. This post will focus on creating a dummy matrix of ingredients that are useful - using an idea from the domain of text mining - TFIDF!
Term Frequency Inverse Document Frequency (TFIDF) is a way of regularizing text data based on how frequent a term is in a sentence versus how frequent it occurs in a document. Intuitively, a word that occurs frequently in the whole document is likely not important to understanding the sentence, unless it occurs very frequently within the sentence. We can use this idea to create a IFICF or a Ingredient Frequency Inverse Cuisine Frequency - this will cause ingredients that are common across cuisines to be down weighted relative to those that are unique to a cuisine.
create_IFICF = function(dt){
dt_sum = dt[,.(term_frequency = sum(term_frequency)),
by = .(ingredient_token, cuisine)]
dt_sum[,cuisine_frequency := uniqueN(.SD$cuisine),
by = .(ingredient_token)]
dt_sum[,total_cuisines := uniqueN(cuisine)]
dt_sum[,inverse_cuisine_frequency := log(total_cuisines/cuisine_frequency)]
dt_sum[,IFICF := term_frequency*inverse_cuisine_frequency]
dt_sum
}After reweighting the data using the above transformation, we get…
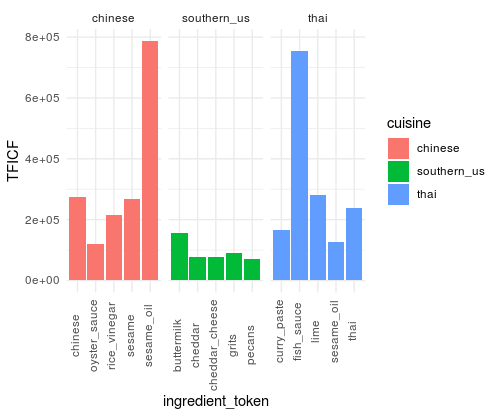
Neat! The plot shows that the IFICF is working like we hoped it would - ingredient terms like sesame
oil and rice vinegar have high scores for Chinese, while buttermilk, pecans, and grits have high
scores for Southern US cuisine. The plot also shows that there is maybe some work to be done around
the ingredient term parsing - as we have both sesame oil and sesame in the top 5 IFICF plot for
Chinese. Ideally these would be collapsed, and in some cases this is possible, but programmatically
this is difficult - is cream the same as whipped cream? I think there may be some ways to fix this
issue by seeing if a term is always part of a bigram or trigram but other tests may be inaccurate.
For now, I’m going to move on and come back as needed.
With the IFICF score in hand - we can now create a prediction matrix with the most predictive N terms and begin modeling! In my next post, I’ll begin the modeling process. If you’d like to see the full data prep workflow see my github